An eigenvector of \(A\) is a nonzero vector \(\mathbf{x}\) in \(\mathbb{R}^{n}\) (or \(\mathbb{C}^{n}\)) such that for some scalar \(\lambda\), we have
\[
A \mathbf{x}=\lambda \mathbf{x}
\]
. . .
Why do we care? One reason: matrix multiplication can become scalar multiplication:
Will see how to use these ideas to understand dynamics even for vectors that aren’t eigenvectors.
Finding Eigenvalues and Eigenvectors
\(\lambda\) is an eigenvalue of \(A\) if \(A \mathbf{x}=\lambda \mathbf{x}\left(=\lambda I \mathbf{x}\right)\)
. . .
\[
\mathbf{0}=\lambda I \mathbf{x}-A \mathbf{x}=(\lambda I-A) \mathbf{x}
\]
. . .
pause
. . .
So, \(\lambda\) is an eigenvalue of \(A\)\(\iff\)\(\operatorname{det}(\lambda I-A)=0\).
. . .
If \(A\) is a square \(n \times n\) matrix, the equation \(\operatorname{det}(\lambda I-A)=0\) is called the characteristic equation of \(A\), and the \(n\) th-degree monic polynomial \(p(\lambda)=\operatorname{det}(\lambda I-A)\) is called the characteristic polynomial of \(A\).
Eigenspaces and Eigensystems
The eigenspace corresponding to eigenvalue \(\lambda\) is the subspace \(\mathcal{N}(\lambda I-A)\) of \(\mathbb{R}^{n}\) (or \(\left.\mathbb{C}^{n}\right)\).
We write \(\mathcal{E}_{\lambda}(A)=\mathcal{N}(\lambda I-A)\).
. . .
Note: \(\mathbf{0}\) is in every eigenspace, but it is not an eigenvector.
. . .
The eigensystem of the matrix \(A\) is a list of all the eigenvalues of \(A\) and, for each eigenvalue \(\lambda\), a complete description of its eigenspace – usually a basis.
. . .
Eigensystem Algorithm:
Given \(n \times n\) matrix \(A\), to find an eigensystem for \(A\) :
Find the eigenvalues of \(A\).
For each scalar \(\lambda\) in (1), use the null space algorithm to find a basis of the eigenspace \(\mathcal{N}(\lambda I-A)\).
A reminder: the Null Space algorithm
Given an \(m \times n\) matrix \(A\).
Compute the reduced row echelon form \(R\) of \(A\).
Use \(R\) to find the general solution to the homogeneous system \(A \mathbf{x}=0\).
. . .
Write the general solution \(\mathbf{x}=\left(x_{1}, x_{2}, \ldots, x_{n}\right)\) to the homogeneous system in the form
A basis for \(\mathcal{E}_{2}(A)\) is \(\{(1,0,0)\}\). Dimension of \(\mathcal{E}_{2}(A)=1\).
Eigenvalue Multiplicity
The algebraic multiplicity of \(\lambda\) is the multiplicity of \(\lambda\) as a root of the characteristic equation. The geometric multiplicity of \(\lambda\) is the dimension of the space \(\mathcal{E}_{\lambda}(A)=\mathcal{N}(\lambda I-A)\).
. . .
The eigenvalue \(\lambda\) of \(A\) is said to be simple if its algebraic multiplicity is 1 , that is, the number of times it occurs as a root of the characteristic equation is 1 . Otherwise, the eigenvalue is said to be repeated.
. . .
For an \(n \times n\) matrix \(A\), the sum of the algebraic multiplicities of all the eigenvalues of \(A\) is \(n\).
(In other words, there are \(n\) eigenvalues, counting algebraic multiplicities and complex numbers).
The geometric multiplicity of an eigenvalue is always less than or equal to its algebraic multiplicity.
Defective Matrices
A matrix is defective if one of its eigenvalues has geometric multiplicity less than its algebraic multiplicity.
. . .
This means that the sum of the geometric multiplicities of all the eigenvalues is less than \(n\).
Similarity and Diagonalization
Functions of Diagonal Matrices
It’s easy to find functions of matrices if the matrix is diagonal.
To diagonalize an \(n \times n\) matrix \(A\), we just need to find \(n\) independent eigenvectors and put them into the columns of a matrix \(P\). Then \(P^{-1} A P=D\)
The \(n \times n\) matrix \(A\) is diagonalizable if and only if there exists a linearly independent set of eigenvectors \(\mathbf{v}_{1}, \mathbf{v}_{2}, \ldots, \mathbf{v}_{n}\) of \(A\)\(\dots\) in which case \(P=\left[\mathbf{v}_{1}, \mathbf{v}_{2}, \ldots, \mathbf{v}_{n}\right]\) is a diagonalizing matrix for \(A\).
. . .
If the \(n \times n\) matrix \(A\) has \(n\) distinct eigenvalues, then \(A\) is diagonalizable.
Caution: Just because the \(n \times n\) matrix \(A\) has fewer than \(n\) distinct eigenvalues, you may not conclude that it is not diagonalizable.
Application to Discrete Dynamical Systems
Diagonalizable Transition Matrices
Suppose you have the discrete dynamical system \[
\mathbf{x}^{(k+1)}=A \mathbf{x}^{(k)}
\]
. . .
Assume \(A\) is diagonalizable, then we can write complete, linearly independent eigenvectors \(\mathbf{v}_{1}, \mathbf{v}_{2}, \ldots, \mathbf{v}_{n}\), with eigenvalues \(\lambda_{1}, \lambda_{2}, \ldots, \lambda_{n}\).
Suppose the eigenvalues are ordered, so that \(|\lambda_{1}| \geq|\lambda_{2}| \geq \cdots \geq|\lambda_{n}|\).
If \(\left|\lambda_{k}\right|=\rho(A)\) and \(\lambda_{k}\) is the only eigenvalue with this property, then \(\lambda_{k}\) is the dominant eigenvalue of \(A\).
Implications of the Spectral Radius
For \(n \times n\) transition matrix \(A\), initial state vector \(\mathbf{x}^{(0)}\):
If \(\rho(A)<1\), then \(\lim _{k \rightarrow \infty} A^{k} \mathbf{x}^{(0)}=\mathbf{0}\).
If \(\rho(A)=1\), then the sequence of norms \(\left\{\left\|\mathbf{x}^{(k)}\right\|\right\}_{k=0}^{\infty}\) is bounded.
If \(\rho(A)=1\) and \(\lambda=1\) is the dominant eigenvalue of \(A\), then \(\lim _{k \rightarrow \infty} \mathbf{x}^{(k)}\) is an element of \(\mathcal{E}_{1}(A)\) – either an eigenvector or \(\mathbf{0}\).
If \(\rho(A)>1\), then for some choices of \(\mathbf{x}^{(0)}\) we have \(\lim _{k \rightarrow \infty}\|\mathbf{x}\|=\infty\)
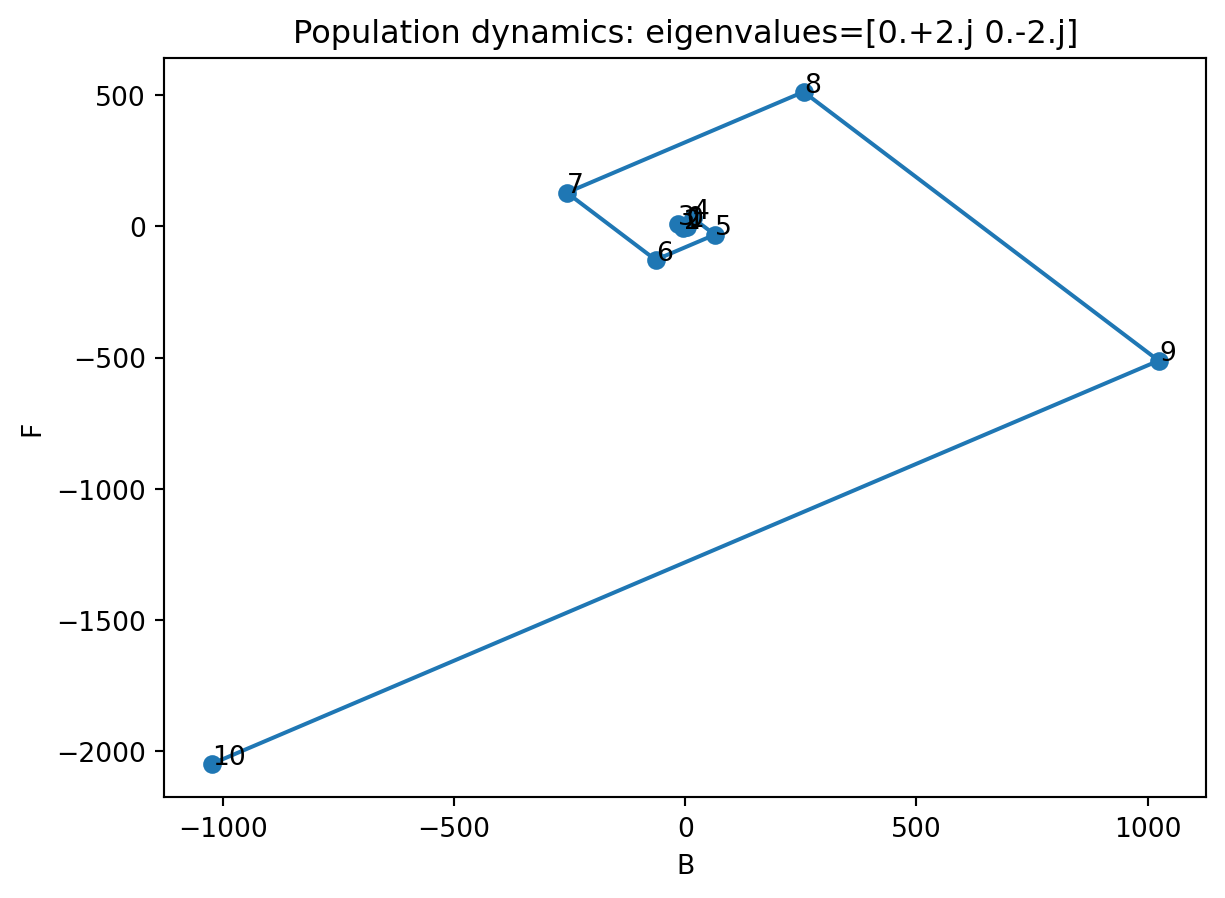
Example
You have too many frogs.
. . .
There is a species of bird that eats frogs. (Yay!) Can these help you with your frog problem?
. . .
Let \(F_{k}\) and \(B_{k}\) be the number of frogs and birds at year \(k\).
x0 = np.array([100, 10000]) def print_iterations(x0, A, n1=10, n2=1): x = x0for i inrange(n1):for j inrange(n2): x = A @ xprint(x)print_iterations(x0, A)
Go back to some of the previous examples we’ve used, or that you’ve used in your projects. Work in pairs to find the eigenvalues and eigenvectors of the transition matrix. What do the eigenvalues tell you about the dynamics of the system?